[转载]Cuckoo Hashing
本文簡單寫了cuckoo hashing的演算法以及後來的發展變形, 在讀了一些文章之後做一些筆記, 圖片都是來自其他文章.
一個合格的hash table必須要包含以下的操作
- Lookup(key) , 查詢一個key是否存在hash table裡
- Insert(key, value), 在table裡寫入一對(key, value)
- Delete(key) , 刪除某個key跟相對應的value
而理想上, 我們期望以上三種操作都可以只要花費O(1)的時間, 但實際上沒這麼順利 : )
如果想要簡單快速的做出一個hash table, 最直接的作法就是allocate一個array, 如果bucket是空的就沒事, 如果bucket裡面已經有key了, 就直接把key串在當前bucket裡的key的最後, 做成一個linked list, 非常容易實作.

chaining hash from WIKI
這個方法的缺點是, 在查詢某個key的時候, 最差狀況下要花費O(n)的時間, n是table裡面的# of key. 但如果hash function選得夠好, 也沒這麼差.
但可以想像如果table裡面的key數量到達某個門檻的時候, collision會越來越常發生, 這個時候就必須要resize之後再做rehash, 也就是加大table size, 降低collision機率. Redis就是這麼做的, 如果load factor到某個比例, 或是linked list的長度到達某個門檻, 就會開始做gradually rehash.
另一個小問題是link-list並不是連續的memory space, 這就無法做cache prefetching.
Cuckoo Hashing是在2001年提出的hash演算法, 算是2 choice hashing的強化版, 分類上屬於Opening address的hash演算法. Opening address的概念是: 如果當前的bucket已經有東西了, 就換一個bucket試試看. 常見的有probing類的方法, 大致上是根據某些規則找下一個可能的bucket, 一直到找到的bucket為空為止.
Cuckoo是一種鳥, 通俗一點叫布穀鳥, 高級一點的說法是杜鵑. 他的叫聲經常被模擬在時鐘上.

cuckoo! cuckoo!
這種鳥有一個缺德的行徑, 就是會把自己的蛋下在別人的窩裡, 讓別人幫自己養小孩. 孵出來的小鳥也不遑多讓, 小杜鵑鳥會偷偷把原本的鳥蛋給踢出窩裡, 使得小孩總量不變, in = out = k.

這套理念套用在hash algorithm裡, 概念就是: 在insert的時候, 如果當前的bucket已經有東西了, 就把原本bucket裡面的key給踢出, 然後被踢出的key用另一套hash function找到另一個bucket, 嘗試insert.
所以在Cuckoo hashing裡面, 我們需要至少兩個獨立的hash function. 一個是主要的, 另外一個是備用的hash function, 用途是在被踢出的時候可以找另外一個家.
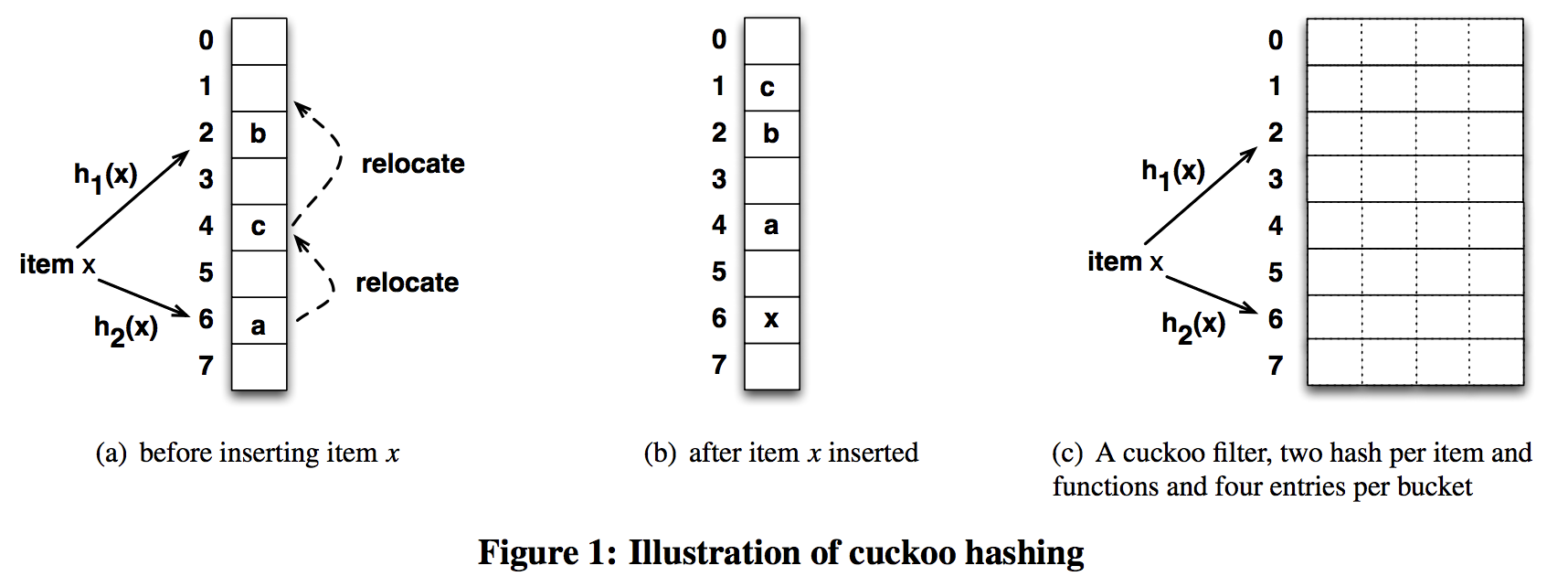
所以insert的流程如圖:
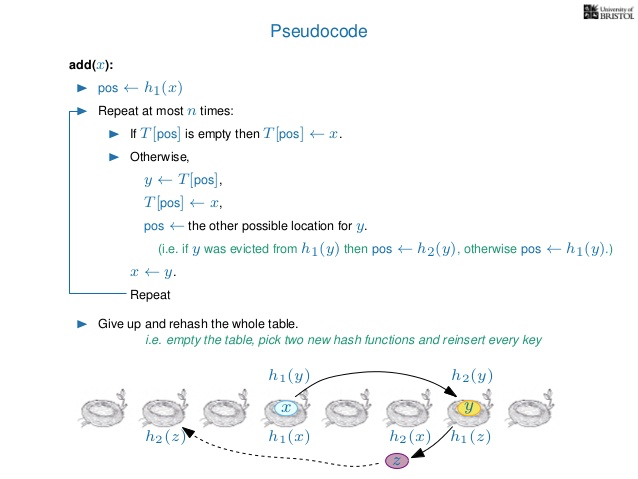
演算法非常簡單易懂, 但應該有一些蠻容易想到的問題:
- Insert的時候, 運氣差的狀況下會不會牽動很多bucket?
會, 但數學上可以證明分攤下來的時間複雜度是O(1). - 會不會有cycle?
會, cycle發生的時候必須做rehash, 如果這時候table內的key不多(occupancy不高), 那可能是hash function太差, 可以換一套hash function試試看. - 在insertion fail發生的時候, capacity如何?
很不幸, 在論文上提到, 當table是一維的時候, insertion fail發生時, 空間利用率大概也就是50%, 60%, 跟其他的hash演算法差不多. 因此一個簡單的變形是: 讓一個bucket一次擁有4個slot, 如果4個slot還沒被填滿之前是不會有key被踢出的. 論文指出如果是4個slot, capacity可以到90%以上.
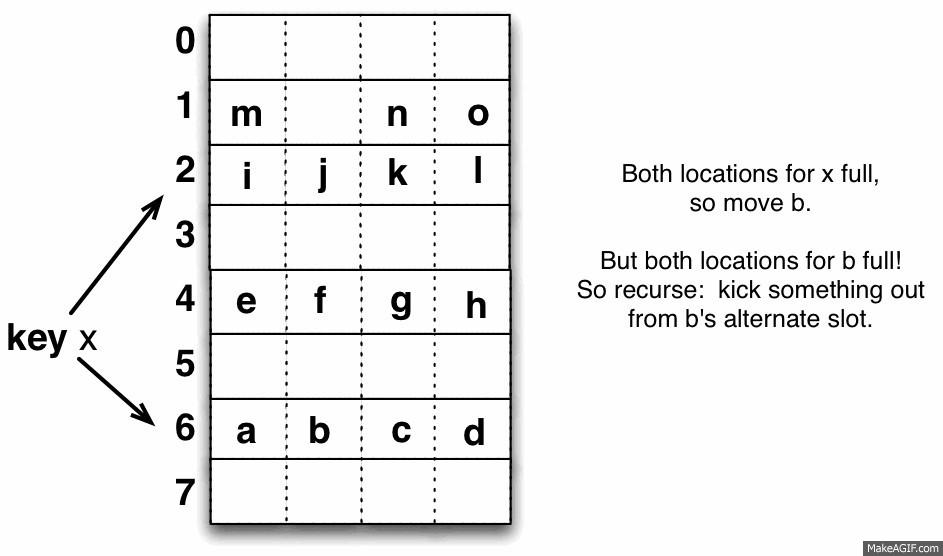
在hash table的三個operation中, 不難想像cuckoo hashing最大的挑戰是insert, 因為lookup/delete非常簡單. 只要檢查兩個hash function裡面的slot有沒有目標的key就可以了. 時間複雜度是O(1).
1 | lookup(key): |
另一項優勢就是, 因為cuckoo hashing的table是二維的array做出來的, 所以非常適合cache prefetching, 比起linked list的效能會好非常多. 而二維array帶來的另一個優勢是, 一塊連續的記憶體非常適合load進GPU做平行運算, 在GPU加持下可以大幅加速.
在cuckoo hashing發表之後, 出現了很多改進跟變形:
- 能不能直接找出最好的cuckoo path, 使得這條path盡可能地短?
事實上, cuckoo hashing可以轉化為graph的問題, 所以找一條最短路徑使得key可以盡快的被安置好, 其實只要先把問題轉成graph, 然後用BFS就可以處理了. key其實就是連接兩個bucket的edge.
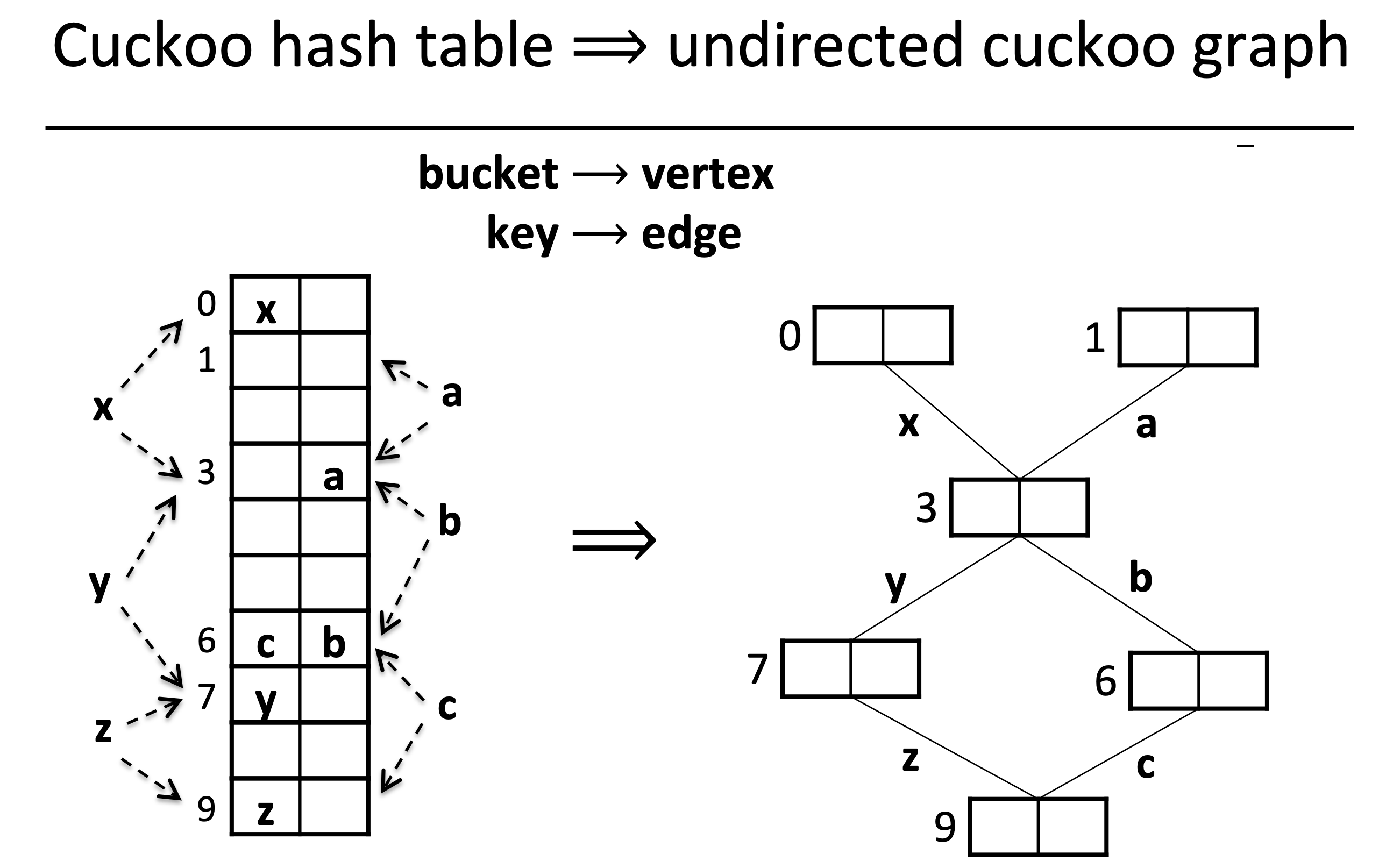
From https://www.cs.princeton.edu/~mfreed/docs/cuckoo-eurosys14-slides.pdf
- 減少lock的影響
由於cuckoo hashding需要做一系列的re-insert, 因此大部分的場景都加了lock避免資料髒掉. 但在libcuckoo中, 用了樂觀鎖來減少lock的次數. 並且是在BFS找完path之後才lock. - Cuckoo Filter
Bloom filter不支援delete, 而改進的counting bloom filter為了計算key的數量, 造成另一個缺點是空間的浪費. 2014年提出的cuckoo filter解決了以上兩個問題, 空間使用率高, 並且支援delete操作, false positive rate也非常低(< 3 %). 實作細節包含了把儲存內容改成fingerprint of given key, 以及對slot裡面的fingerprint做排序等等.
Reference:
- https://da-data.blogspot.com/2013/03/optimistic-cuckoo-hashing-for.html
- http://www.cs.cmu.edu/~binfan/papers/conext14_cuckoofilter.pdf
- https://www.cs.princeton.edu/~mfreed/docs/cuckoo-eurosys14-slides.pdf
- https://www.slideshare.net/BenjaminSach/hashing-part-two-cuckoo-hashing
- https://rocksdb.org/blog/2014/09/12/cuckoo.html
- https://lrita.github.io/2020/02/11/cuckoo-hashing-filter/#d-cuckoo-hashing
- http://pkqs.net/~tre/diplomarbeit.pdf
- https://zhuanlan.zhihu.com/p/21812636
- https://github.com/seiflotfy/cuckoofilter
- https://github.com/efficient/libcuckoo