Count-Min Sketch
introduction
Count-min Sketch 是一个概率数据结构,用作数据流中事件的频率表。它使用散列函数将事件映射到频率,但与散列表不同,散列表仅使用子线性空间,但会因过多计算冲突导致的某些事件。
Count-min Sketch 本质上与 Fan 等人在 1998 年引入的计数 Bloom filter 相同的数据结构. 但是,它们的使用方式各不相同,因此尺寸也有所不同:计数最小草图通常具有次线性单元数,与草图的所需近似质量有关,而计数 Bloom filter 的大小通常与其中的元素数集合。
Main aim is to count things, how many times have i seen an element
structure
实际的草图数据结构是 w 列和 d 行的二维数组。参数 w 和 d 在创建草图时是固定的,并确定时间和空间需求以及在查询频率或内部产品草图时的错误概率。与每个 d 行相关联的是一个单独的散列函数; 哈希函数必须是成对独立的。参数 w 和 d 可以通过设置 w =⌈e/ε⌉和 d =⌈ln1 /δ⌉来选择,其中在回答查询时的误差在概率为 1 - δ的附加系数ε内(见下文) ,e 是欧拉数。
- 结构图

对于 Hash Function 的要求,可以是最简单的 hash function ,但所有的 hash function 必须不同.
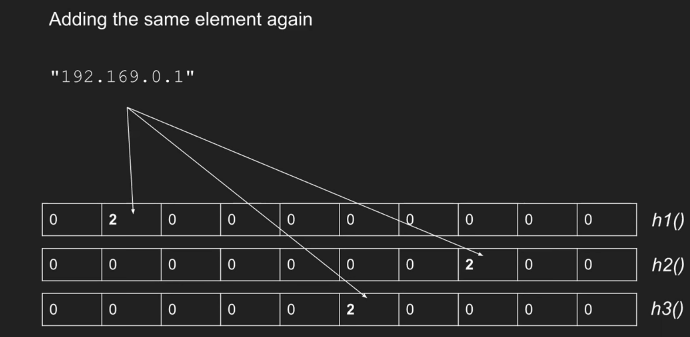
添加元素
当一个新的类型 i 事件到达时,我们更新如下:对于表中的每一行 j,应用相应的散列函数来获得列索引 k = hj(i)。然后将第 j 行第 k 列中的值加 1。
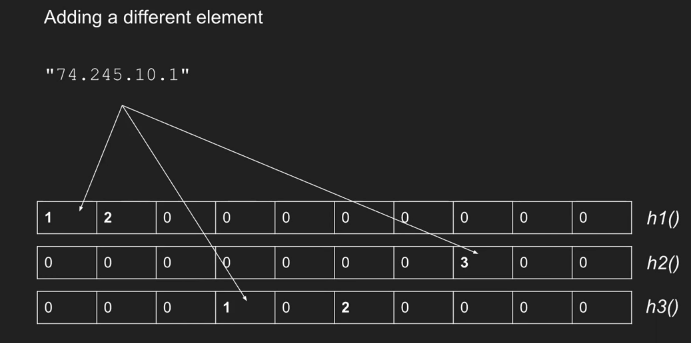
查询(统计元素个数)
The estimated count is given by the least value in the table for i, namely {\displaystyle {\hat {a}}{i}=\min {j}\mathrm {count} [j,h{j}(i)]} {\hat a}{i}=\min {j}{\mathrm {count}}[j,h{j}(i)], where {\displaystyle \mathrm {count} } {\mathrm {count}} is the table.
就是取最小的 count 作为 element 出现的次数,故名 count-min

Probabilistic problem
Epsilon: accepted error added to counts with each item
Delta: probability that estimate is outside accepted error
use cases
- any kind of frequency tracking
- NLP (word count)
- Extension heavy-hitters
- range-query