C++ 宏编程 学习笔记¶
虽然很多人提出不要在C++中使用宏,但是宏对C/C++的作用却是至关重要的!
对C++语言进行改造,肯定是要用到宏的,不精通宏,怎么好意思说自己精通C++?
看看任何一个高级C++库,全部都遍地是宏!
心得总结
C++宏最重要是明确:”宏仅仅是文本替换!而且它是预编译时发生,在正常编译开始之前”。
详细手册
宏是什么?
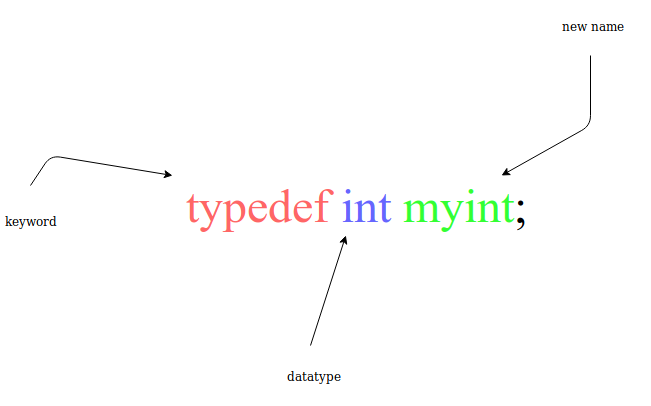
宏就是编译器在预处理阶段进行的 文本替换 。 习惯上用大写字母表示<宏名>,目的是为了与变量名区分。常量用大写字母;变量用小写字母。 #define PI 3.1415926
如果某一个标识符被定义为宏名后,在取消该宏定义之前,不允许重新对它进行宏定义。 所以应记得及时的尽量取消宏定义: #undef <标识符> 。 #undef 比较多的用途是在使用宏之前先进行 #undef 以保证这个宏不会与先前的定义冲突。
使用宏做函数
宏可以像函数一样被定义,例如:
1 | #define MIN(x,y) ((x)<(y)?(x):(y)) |
但是在实际使用时,只有当写上MIN(),必须加括号,MIN才会被作为宏展开,否则不做任何处理。 编译器(预处理器)对宏只进行简单的文本替换,而 不会进行语法检查 ,所以更多的检查性工作得你自己来做。
为什么要用宏来做函数?
- 鸭子原则:比如MIN宏适用于任何实现了operator<的类型,包括自定义类型(这点与template类似);
- 效率最高:虽然使用inline提示符也将函数或模板定义为内联的,但这只是一种提示而已,到底编译器有没有优化还依赖于编译器的实现,而使用宏函数则是完全由代码本身控制。
2个宏编程易犯的错误
程序员对宏定义的使用要非常小心,特别要注意两个问题:
谨慎地将宏定义中的 “参数” 和 整个宏 都用括弧括起来。
所以,严格地讲,下述解答:
#define MIN(A,B) (A) <= (B) ? (A) : (B) #define MIN(A,B) (A <= B ? A : B )都应判0分; 正确的解答应该是:#define MIN(A, B) ((A) <= (B) ? (A) : (B))防止宏的副作用 :
宏定义
#define MIN(A,B) ((A) <= (B) ? (A) : (B))对MIN(*p++, b)的作用结果是:((*p++) <= (b) ? (*p++) : (*p++))这个表达式会产生副作用,指针p会作三次++自增操作。 (因为, 宏的本质是文本替换 )除此之外,另一个应该判0分的解答是:#define MIN(A,B) ((A) <= (B) ? (A) : (B));这个解答在宏定义的后面加”;”,显示编写者对宏的概念模糊不清,只能被无情地判0分并被面试官淘汰。
后面加不加分号:
宏定义一般都不在最后加分号,调用的时候才加分号。 这样处理之后就要求使用者将宏视为一条普通语句而不是一个宏,从而需要在后面加上;号。
特殊符号:#、##
# 符号把一个符号直接转换为字符串,例如:
1
2#define STRING(x) #x;
const char *str = STRING( test_string );str的内容就是”test_string”,也就是说 #会把其后的符号直接加上双引号 , 即STRING( test_string )被扩展为 “test_string” 。
##符号会连接两个符号,从而产生新的符号(词法层次),例如:
1
2#define SIGN( x ) INT_##x
int SIGN( 1 );宏被展开后将成为:int INT_1;
有资料说可以用#@把一个宏参数变成字符(也就是给参数加上单引号,相对应于#的双引号) #@a = 'a' 但是,在gcc上的测试显示不支持#@,测试的结果是”“@,相当于对空添加双引号再加上@的结果。
VA_ARGS 变参宏
这个比较酷,它使得你可以定义类似的宏:
1 | #define myprintf(templt,...) fprintf(stderr,templt,__VA_ARGS__) |
第一个宏中由于没有对变参起名,我们用默认的宏VA_ARGS来替代它。 第二个宏中,我们显式地命名变参为args,那么我们在宏定义中就可以用args来代指变参了。
由于可变参数应该可以为空,所以在只能提供一个参数时,普通的调用方式会引起编译错误。 myprintf("abc"); 会被替换为 fprintf(stderr, "abc", ); 这是语法错误,解决方法小变通一下:
1 | #define myprintf(templt, ...) fprintf(stderr,templt, ##__VAR_ARGS__) |
于是 myprintf("abc"); 会被替换为 fprintf(stderr, templt, ""); 就没有问题了。 VA_ARGS是系统预定义宏,被自动替换为参数列表 。
得到VA_ARGS具体有多少个参数
得到VA_ARGS里具体有多少个参数有时候很有用,这个解决方案在gcc下可以这样做到:
#define PP_NARG(...) PP_NARG_(__VA_ARGS__, PP_RSEQ_N()) #define PP_NARG_(...) PP_ARG_N(__VA_ARGS__) #define PP_ARG_N( \ _1, _2, _3, _4, _5, _6, _7, _8, _9,_10, \ _11,_12,_13,_14,_15,_16, N, ...) N #define PP_RSEQ_N() \ 16,15,14,13,12,11,10, \ 9,8,7,6,5,4,3,2,1,0然后cout << (PP_NARG(1,2,3,4,1,1)) << endl;就可以得到具体的参数数目6。这里实现的非常漂亮,原理也很直观,就是把VA_ARGS与倒序的PP_RSEQ_N组合在一起,这个组合的结果相当于把VA_ARGS向后推了x位,这个x就是变参的个数,于是再获取第17位就可以得到这个x了,具体的宏展开如下:PP_NARG(1,2,3,4,1,1) => PP_NARG_(1,2,3,4,1,PP_RSEQ_N()) PP_NARG_(1,2,3,4,1,PP_RSEQ_N()) => PP_NARG_(1,2,3,4,1,1,16,15,14,...,3,2,1,0) PP_NARG_(1,2,3,4,1,1,16,15,14,...,3,2,1,0) => PP_ARG_N(1,2,3,4,1,1,16,...,3,2,1,0) PP_ARG_N(1,2,3,4,1,1,16,15,14,13,12,11,10,9,8,7,6,5,4,3,2,1,0) => 6
宏不支持递归
当一个宏自己调用自己时,会发生什么?例如: #define TEST( x ) ( x + TEST( x ) )
再调用 TEST( 1 ); 会发生什么?
为了防止无限制递归展开,语法规定, 当一个宏遇到自己时,就停止展开 。也就是说,当对TEST( 1 )进行展开时,展开过程中又发现了一个TEST,那么就将这个TEST当作一般的符号。TEST(1)最终被展开为: 1 + TEST( 1) 。
宏从内向外展开
宏参数的prescan,当一个宏参数被放进宏体时,这个宏参数会首先被全部展开(有例外,见下文)。当展开后的宏参数被放进宏体时,预处理器对新展开的宏体进行第二次扫描,并继续展开。例如:
1 | #define PARAM( x ) x |
因为ADDPARAM( 1 ) 是作为PARAM的宏参数,所以先将ADDPARAM( 1 )展开为INT_1,然后再将INT_1放进PARAM。
当一个宏对它的某个参数进行#或者##时, 这个参数使用点并不被替换为展开后的文本 ,然而解决这个问题的方法很简单,一般就是加多一层 中间转换宏 。
例外情况是,如果PARAM宏里对宏参数使用了#或##,那么宏参数不会被展开:
1 | #define PARAM( x ) #x |
使用这么一个规则,可以创建一个很有趣的技术:打印出一个宏被展开后的样子,这样可以方便你分析代码:
1 | #define TO_STRING( x ) TO_STRING1( x ) |
TO_STRING首先会将x全部展开(如果x也是一个宏的话),然后再传给TO_STRING1转换为字符串,现在你可以这样: const char *str = TO_STRING( PARAM( ADDPARAM( 1 ) ) ); 去一探PARAM展开后的样子。
这种中间层展开的技巧在宏编程中会经常经常地用到!不过有了Eclipse的”Ctrl + =”进行宏展开的功能,这样打印一个宏就显得落后了。
注意:
- 在#后面的宏形参和在##两旁的宏形参都不会再被展开了!
- 只展开参数中的宏,而宏体中的宏会当作普通字符串来处理的
宏展开时的限制
警告
有下面的限制的根本原因就是上一条中的2点:
- 在#、##旁边不会展开
- 只会展开参数中的嵌套宏
从以下这个定义匿名变量的宏 必须拥有三层 的原因开始讲起:
1 | #define ANONYMOUS1(type, line) type _anonymous##line |
原理: 嵌套的宏只有在它处于参数的位置时,且不在##的旁边,才会去解开! :
- 在第一层时,LINE根本不处于宏参数的位置,所以它不会解开,而是作为一个字符串传递给了第二层;
- 在第二层时,line参数被替换为LINE,而且这个LINE处于宏参数中,且不在##的旁白,所以会被解开变成相应的行编号,如168;
- 在第三层时,才可以真正的生成static int __anonymous168
这里 必须要有三层才能做到,为什么二层做不到呢? 因为,如果试图在第二层就展开成最后的变量声明式,那么就是试图这样:
1 | #define ANONYMOUS(type) ANONYMOUS1(type, __LINE__) |
因为第一层不可能展开LINE,所以在第二层时的line还仅仅是LINE宏,但是不幸的是它在##的后面,因此又得不到展开,所以最后会变成static int _anonymouse__LINE__,当然错了!
常用的预定义宏
ANSI标准说明了五个预定义的宏名。它们是: LINE、FILE、DATE、TIME、TIMESTAMP、STDC、__cplusplus
gcc中还定义了 __func__ 可以标识当前的函数名,debug编译时还定义了 _DEBUG 宏。
如果编译器不标准的,则可能仅支持以上宏名中的几个,或根本不支持,也可能提供其它预定义的宏。
- LINE 及 FILE 宏指示,#line指令可以改变它的值,简单的讲,编译时,它们包含程序的当前行数和文件名(#line一般很少用)。
- DATE 宏指令含有形式为月/日/年的串,表示源文件被翻译到代码时的日期。
- TIME 宏指令包含程序编译的时间。时间用字符串表示,其形式为: 分:秒
- TIMESTAMP 包含当前源文件的最后修改时间,在自动化编译时肯定常用。
- STDC 宏指令的意义是编译时定义的。一般来讲,如果STDC已经定义,编译器将仅接受不包含任何非标准扩展的标准C/C++代码。如果实现是标准的,则宏STDC含有十进制常量1。如果它含有任何其它数,则实现是非标准的。
- __cplusplus 与标准c++一致的编译器把它定义为一个包含至少6为的数值。与标准c++不一致的编译器将使用具有5位或更少的数值。
注意事项
- 普通宏定义
- 宏名一般用大写
- 使用宏可提高程序的通用性和易读性,减少不一致性,减少输入错误和便于修改。
- 预处理是在编译之前的处理,而编译工作的任务之一就是语法检查,预处理不做语法检查。
- 宏定义末尾不加分号;
- 宏定义写在函数的花括号外边,作用域为其后的程序,通常在文件的最开头。
- 可以用#undef命令终止宏定义的作用域
- 宏定义可以嵌套
- 字符串”“中永远不包含宏
- 宏定义不分配内存,变量定义分配内存。
- 带参宏定义
- 实参如果是表达式容易出问题
- 宏名和参数的括号间不能有空格
- 宏替换只作替换,不做计算,不做表达式求解
- 函数调用在编译后程序运行时进行,并且分配内存。宏替换在编译前进行,不分配内存
- 宏的哑实结合不存在类型,也没有类型转换。
- 函数只有一个返回值,利用宏则可以设法得到多个值
- 宏展开使源程序变长,函数调用不会
- 宏展开不占运行时间,只占编译时间,函数调用占运行时间(分配内存、保留现场、值传递、返回值)
高级技巧
do{…}while(0)技巧
这个技巧非常漂亮!
使用do-while(0)的宏定义是为了防止if-else( if)的语法错误,这一般是库作者来保证代码的健壮性所使用的技巧。 而且,还 可以使得宏中使用到的变量都成为 局部变量 ,不造成任何副作用!
这里用一个简单点的宏来演示: #define SAFE_DELETE(p) do{ delete p; p = NULL} while(0) 假设这里去掉 do...while(0), 于是这样定义: #define SAFE_DELETE(p) delete p; p = NULL; 。 那么以下代码:
1 | if(NULL != p) SAFE_DELETE(p) |
就有两个问题,
- 因为if分支后有两个语句,else分支没有对应的if,编译失败
- 假设没有else, SAFE_DELETE中的第二个语句无论if测试是否通过,会永远执行。
你可能发现,为了避免这两个问题,我不一定要用这个令人费解的do…while, 我直接用{}括起来就可以了 #define SAFE_DELETE(p) { delete p; p = NULL;}
的确,这样的话上面的问题是不存在了,但是我想对于C++程序员来讲,在每个语句后面加分号是一种约定俗成的习惯,这样的话,以下代码:
1 | if(NULL != p) SAFE_DELETE(p); |
其else分支就无法通过编译了(原因同上),所以采用do…while(0)是做好的选择了。
也许你会说,我们代码的习惯是在每个判断后面加上{}, 就不会有这种问题了,也就不需要do…while了,如: if(...) {...}else{...}
诚然,这是一个好的,应该提倡的编程习惯,但一般这样的宏都是作为library的一部分出现的,而 对于一个library的作者,他所要做的就是让其库具有通用性,强壮性,因此他不能有任何对库的使用者的假设,如其编码规范,技术水平等 。
总结的说,这种do{…}while(0)技巧有以下优点:
- 在宏定义中可以使用局部变量;
- 在宏定义中可以包含多个语句,但可以当作一条语句使用。如上述if结构中的代码,如果没有do-while把多条语句组织成一个代码块,则程序的运行结果就不正确,甚至不能编译。
使用宏完成注册操作
经常需要对对新建的或派生的类进行注册操作,比如MAPREDUCE_REG、TEST(gtest)等。
这类操作需要通知库代码来调用自己的类执行某些操作,而且这种注册操作一般是在非函数区域中声明,即函数外进行声明。如何做到在函数区域外声明时还能保证执行某段代码?
这就需要利用 C++标准保证全局变量一定会在main开始之前准备好,因此可以利用全局变量的构造函数来执行代码:
1 |
|
使用的时候就是这样: REG(MyClass); 就会在RegisterManager的RegisterMap里插入一个MyClass对象的指针,这样就完成了注册操作。
gtest中的TEST宏做的更漂亮,它使用了静态成员变量来替代那个全局变量完成了注册操作,并把用户的代码扩展为虚函数的代码
1 |
|
第8行:这里完成注册操作
第9行:非常酷,用户的代码就变成了虚函数Fun的代码
使用方式如下:
1 | TEST(abc) { |
常见用途
宏常量:但是如果仅仅是定义常量,那么应该果断的使用const而不是使用宏。
头文件的重复包含:这个用途几乎不用说了,头文件都需要用宏包含起来以免重复包含。
条件编译:生成一个程序的不同版本、或者对debug和release使用不同的代码时非常常见:
1
2
3
4
5
6
7
8
9#if defined(OS_HPUX) && (defined(HPUX_11_11) || defined(HPUX_11_23)
// for HP-UX 11.11 and 11.23
#elif defined(OS_HPUX) && defined(HPUX_11_31
// for HP-UX 11.31
#elif defined(OS_AIX)
// for AIX
#else
...
#endif使用_DEBUG进行一个调试工作:
1
2
3#ifdef DEBUG
printf("Debug information\n");
#endif宏函数:避免函数调用,提高程序效率。宏函数基本上可以被模板和内联函数所取代,但是还是有一些简单的函数会使用宏,而且宏函数可以确保一定是内联的。
引用编译期数据:这种情况只能使用宏来解决了:
1
#define SHOW_CODE_LOCATION() cout<<__FILE__<<':'<<__LINE__<<'\n'
当然,最NB的功能肯定是自动生成代码